Working in a games company often allows you to work with the coolest toys. One of these is a product caled Telemetry from Rad Game Tools.
Python integration
We’ve integrated Telemetry into the game engine for performance evaluation purposes. As part of this, I also integrated it to the Python library. I wrote a special “TelemetryProfiler” class that we can use with sys.setprofile() so that .py excecution can be monitored. In addition, I added some select monitoring hooks into the core engine, and around such places as locks and for memory allocations.
To work well with threads and tasklets, we maded some changes to allow for global profiling. Using a flag called stackless.globaltrace, sys.setprofile() (and sys.settrace()) have global effects on both all tasklets and all threads. The profiling flag is stored in the interpreter state so that new threads will inherit it, and currently executing threads will have it set by traversing the list of existing threads. This allows us to turn profiling on and off in an executing program and monitor all that the python engine is doing.
For profiling stackless tasklets, we had to resort to trickery. Because Telemetry knows about threads, but not microthreads, we had to add code to recognize the currently running tasklet, and unwind and replay the context stack as necessary whenever at tasklet switch occurred.
Here is a snapshot of parts of a Python execution as it is displayed in the Telemetry vizualizer:

Notice the hierarchical call graph. Tooltips will show more information about each field, such as Python source file and line number. The Mem Events bar at the bottom shows all memory allocations made and the lifetime of each of them.
Notice also the red blips. These are the GIL being ticked (there is definitely room for a faster GIL tick function. We already treat the GIL differently from other locks and an optimized Tick is simple to add. Later.)
Condition Variables.
As previously mentioned on this blog, we have to perform HTTP requests on worker threads and then communicate the results back to the main tasklet. The worker threads live in a threadpool and receive work from any client thread. Dispatching of work requests is done using the tried and tested Condition Variable model, using the threading.Condition class and an associated threading.RLock object. Workers wait on condition variables until they are woken up and see that there is work to be done, at which point they pull work off a queue, release the lock, perform the work, and then do it again.
To lower latency, it is important that this dispatching of work to the worker thread happens as soon as possible. Ideally, it should happen immediately, the worker grabbing the GIL, kicking the HTTP Request into action, releaseing the GIL and blocking. To see if things were progressing in a timely manner, I examined the process using Telemetry.
First off, I should explain what locking model we are using. The PS3 is essentially posix-like, so locks (and the GIL) are implemented using the thread_pthread.h file. The default choice in there is to use the posix semaphore API to implement the non-recursive locks Python uses. But I was quickly slapped by the engine profilers when they started seeing all those kernel transitions coming out of Python. Aqcuiring a free lock, and ticking the GIL, when these are based on a semaphore, incurs a kernel transition and scheduling and whatnot, a high price to pay when there is no contention. This lights up red in all performance measurement tools. So, we opted for using the mutex/condition implementation also provided. Why this is not the default in Python is beyond me, since it is much faster.
So, anyway, this is what waking up on a condition variable looks like in Telemetry. The worker thread has been waiting on a threading.Condition object. The main posts a request and the worker wakes up.

What you see on the left is an acquire() in progress. This is the Lock object that the condition variable uses to sleep on. Then, we _acuire_restore(), then some logging code and finally the httpRequest being sent. (Ignore the logging code and its associated GIL delay, it is only used during debugging.)
Zooming in a bit, brings more detail:

What you see here, is the GIL being acquired two times: Once to complete the Lock.acquire() call which is done in Condition.wait(), and once to re-acquire the lock associated with the condition variable (typically an RLock): To complete the condition variable protocol and return from wait() with the lock held.
Now, in a multithreaded program, the GIL is always in contention. Releasing and reaquiring the GIL two times instead of once will therefore add unnecessary latency into this code. If this second GIL aquisition were skipped, this wakeup delay would have been shortened by 10 milliseconds, kicking off the http request that much faster.
Optimization one: _acquire_cv()
The first obvious thing to do is to roll this double acquisition of a lock into one. There are two locks that need to be acquired here, the wait lock and the lock associated with the Condition object. There is no reason they can’t be both acquired in one swell foop.
I did this by adding a new method to the Lock class in thread.c: _acquire_cv() takes an additional Lock object which is always acquired before returning from the function, except when the a try-aquire fails (to support the emulated timeout behaviour.)
Now, if the outer lock is acquired on return, there is no need for an _acquire_restore() call in threading.py, so this has been replaced with a _restore() call, which merely sets the internal variables on an already acquired lock.
This is what the new Condition.wait call looks like:
def wait2(self, timeout=None):
if not self._is_owned():
raise RuntimeError("cannot wait on un-acquired lock")
waiter = _allocate_lock()
waiter.acquire()
self.__waiters.append(waiter)
saved_state = self._release_save()
gotit = 0
try: # restore state no matter what (e.g., KeyboardInterrupt)
if timeout is None:
gotit = waiter._acquire_cv(1, saved_state[0])
if __debug__:
self._note("%s.wait(): got it", self)
else:
pass # removed for brevity
finally:
if gotit:
self._restore(saved_state)
else:
self._acquire_restore(saved_state)
wait = wait2
With this in place, things look a little different:
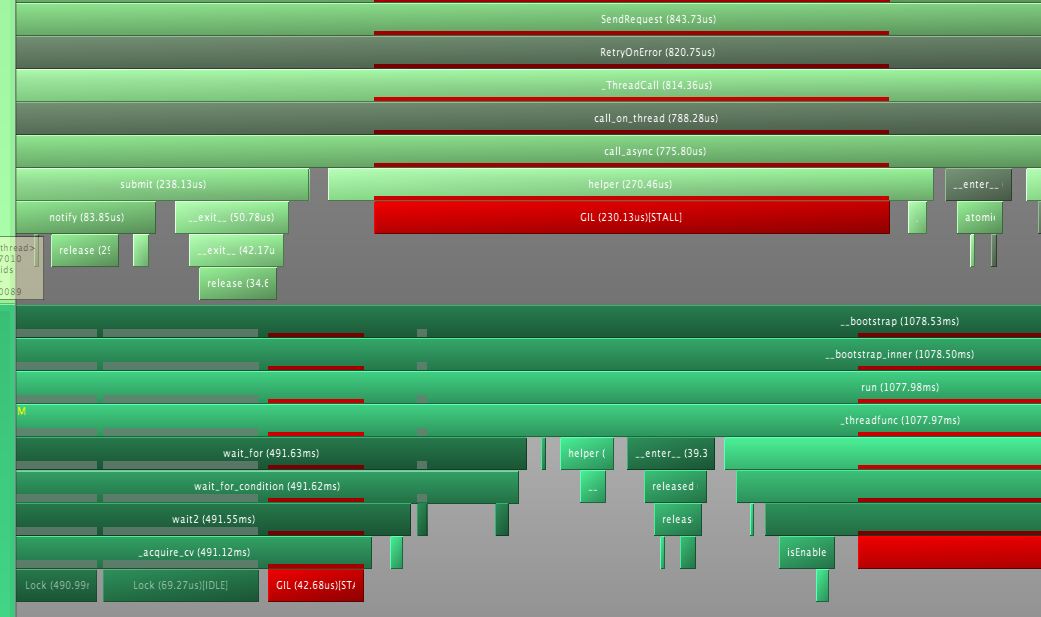
On the bottom left, two Lock regions are visible (this is when acquiring a thread.Lock object.). Once the first has been acuired, i.e. the wakeup signal recieved, it proceeds to aquire the outer lock. This succeeds once the first thread (above in the picture) has released it, in the __exit__ method of a context manager. Once that is done, a single GIL reaquisition is performed. Now, this one is fairly short and some can be longer than this, but it is clear that doing this once, rather than twice is beneficial since it reduces the thrashing of threads involved.
This simple change is really easy to implement. the _acquire_cv() function is simple, and the wait2() function is simpler than the wait() function in threading.py. This is something I’d immediately recommend for cPython.
Native Condition objects
So, is there anything else that can be done? Yes there is. The Condition class is implemented in threading.py by using Python’s native non-recursive locks (semantically, they are semaphores with a max value of 1) and juggling a queue and waking things up. This is what calling condition.wait() looks like:

On the left, there is a lot of action where a Lock object that is used for waiting is being created and put into a list. Then there is a long stall when the initial lock is aquired. Why is that? It’s because every Lock.acquire() releases the GIL, even if the lock is uncontested. It is the nature of the internal architecture of cPython that Lock objects are GIL unaware, so the GIL manipulation must be done outside of them. So, to aquire our our new wait object, the GIL is released, the lock acquired, and then the GIL must be reaquired.
It would be possible here to use the new _acquire_cv() to do this without releasing the GIL, perhaps by passing None as its second argument. But since I’m already using Locks based on mutexes and condition variables, why not simply implement a native Condition object? Doing that would rid us of most of the annoying code in threading.Condition. No need to create a Lock object for every wait, manage a queue, and potentially leave Lock object in an aquired state when destroying them (yes, the timeout version of Condition variables in Python 3 has that race problem.) Also, we would get the built-in timeout mechanism of all condition variable implementations I’ve seen for free.
Since the native Python lock objects are non-recursive, unlike classical mutex objects as used with condition variables, blocking is implemented with an internal Condition variable for each lock. So, a native thread.Condition class’s wait() method cannot directly just pass in a mutex. Instead, we must roll some of our lock release() and acquire() release machinery into the wait() and notify() functions.
This is what the thread.Condition.wait() function looks like:
int
PyThread_cond_wait(PyThread_type_condition *cond, PyThread_type_lock lock, double timeout)
{
/* Release the Lock, keeping the Mutex held */
* no need to release GIL here, this is a short lived thing
*/
pthread_lock *thelock = (pthread_lock *)lock;
int status;
PyTmEnter(PYTM_ENTER_IDLE, "COND");
status = pthread_mutex_lock( &thelock->mut );
CHECK_STATUS_COND;
if (!thelock->locked) {
pthread_mutex_unlock( &thelock->mut );
PyErr_SetString(PyExc_RuntimeError, "cannot wait on un-acquired lock");
return -1;
}
thelock->locked = 0;
status = pthread_cond_signal(&thelock->lock_released);
if (status) {
thelock->locked = 1;
pthread_mutex_unlock( &thelock->mut );
CHECK_STATUS_COND;
}
/* now, wait for the condition variable */
Py_BEGIN_ALLOW_THREADS
if (timeout >= 0) {
struct timespec ts;
#if SN_TARGET_PS3
sys_time_sec_t sec;
sys_time_nsec_t nsec;
sys_time_get_current_time(&sec, &nsec);
ts.tv_sec = sec;
ts.tv_nsec = nsec;
#endif /* todo: implement posix */
ts.tv_sec += (int)timeout;
ts.tv_nsec += (int) 1e9 * (timeout - (double)(int)timeout);
status = pthread_cond_timedwait(cond, &thelock->mut, &ts);
if (status == ETIMEDOUT)
status = 0; /* don't specifically signal this */
} else {
status = pthread_cond_wait(cond, &thelock->mut);
}
/* now, reacquire the lock. We already hold the mutex. */
while (thelock->locked) {
int status2 = pthread_cond_wait(&thelock->lock_released, &thelock->mut);
if (status2) {
if (!status)
status = status2; /* otherwise, ignore this error */
break;
}
}
thelock->locked = 1;
pthread_mutex_unlock( &thelock->mut );
Py_END_ALLOW_THREADS
PyTmLeave();
CHECK_STATUS_COND;
return 0;
}
Similarly, the notify() method must hold the mutex when called:
static int
_PyThread_cond_notify_some(PyThread_type_condition *cond, PyThread_type_lock lock, int all)
{
pthread_lock *thelock = (pthread_lock *)lock;
int status = pthread_mutex_lock( &thelock->mut );
CHECK_STATUS_COND;
if (!thelock->locked) {
pthread_mutex_unlock( &thelock->mut );
PyErr_SetString(PyExc_RuntimeError, "cannot notify on un-acquired lock");
}
if (all)
status = pthread_cond_broadcast(cond);
else
status = pthread_cond_signal(cond);
pthread_mutex_unlock( &thelock->mut );
CHECK_STATUS_COND;
return 0;
}
So, what effect does this have? This is what thread.Condition.wait() looks like in telemetry:

There are some blips on the left when calling the initial predicate in the wait_for_condition() function and the call of the threading.RLock._save() method (to store the recursion state of the RLock.) There is no unnecessary flapping of the GIL.
When waking up, it looks like this when the notify() call is made from the main thread:

And here the worker finally aquires the GIL:

Internally, the notify() call causes the native condition variable to wake up. The delay until it tries to reaquire the GIL is the when it is trying to aquire the associated RLock object. Then once the GIL is finally aqcuired, there is a call to _restore (to restore the recursion state of the RLock) and a finall call to the predicate function to make sure that the the external conditions are now satisfied. In the whole wait() and notify() process, there is no GIL trashing whatsoever.
Conclusion
It is fairly straightforward to modify the native locks in Python to cater to the special semantics required for threading.Condition objects, by adding a special method to acquire two locks at once, and also by acquiring a lock that is known to be uncontested by not releasing the GIL.
For those lock implementations that rely on mutexes and condition variables, it is also simple to provide a native implementation of a Condition object. Currently this applies to pthreads only, but I have a condition variable / mutex locking implementation waiting in the wings for Windows, which would make the same thing possible there (and in fact our CCP branch of cPython 2.7 does just that).
threading.py can easily use these new features if available and fall back to the old behaviour if not.
The only semantic change when providing a native Condition variable is that then the python condition variable may become subject to spurious wakeup. While python has never promised that spurious wakeup cannot occur, the implementation in threading.py has been free of it. However, the condition variable, as derived from the monitor concept, has always been careful to allow for spurious wakeups as a possibility. There are good reasons for it, and since stolen wakeups are always a possibility regardless, and the correct way of using wait() is in a loop, checking an external condition, it does not matter to the conforming programmer.
We’ll be going forward by using the native Condition implementation on the PS3 to increase synergy, and drill down to better leverage towards a procured paradigm shift vis-à-vis a deliverable home run.

Hi,
nice article, thanks. I’ve found using a non-python queue is quite useful for speeding up things. The worker threads can insert into the queue without obtaining the python GIL. Works nicely if your worker code is mostly C stuff. Seems like you’ve sped up the python side queue stuff quite a lot where that might not be necessary anymore.
Yes, in many other cases we have non-python worker threads and then can keep the queueing non-Python. In this case, I specifically wanted to use Python worker threads to spare me some pain.
One particularly bothersome thing with using non-python workers, is that object lifetime management becomes more difficult, since the worker cannot use reference counting. For example, the worker needs its own reference to arguments, or needs to copy them, because the client may get killed before the worker exits.