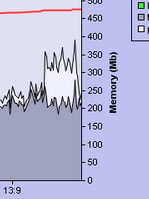
As Richard Tew mentioned on his blog, we are using the lazy importing trick to reduce memory overhead.
We improved the original module by adding some features:
- A simpler and more robust injection mechanism using gc.get_referrers()
- Supporting zip imports
- Supporting reload()
- A reporting capability.
- Supporting bypassing selected modules or packages.
The last bit is important because some modules may be used internally by C and those cannot be treated with this. In our case, we actually import this module from C right after importing site.py, in order to get maximum benefit, so we may be seeing more problems than the casual user who imports it from a .py file.
I don’t have any other good place to put this, so I’m just leaving it here for the time being.
[python]
# Copyright rPath, Inc., 2006
# Available under the python license
“”” Defines an on-demand importer that only actually loads modules when their
attributes are accessed. NOTE: if the ondemand module is viewed using
introspection, like dir(), isinstance, etc, it will appear as a
ModuleProxy, not a module, and will not have the correct attributes.
Barring introspection, however, the module will behave as normal.
“””
# modified for CCP by Kristján Valur Jónsson:
# – Use the gc.getreferrers() method to replace module references
# – Add zip support
# – support reload()
# – Add reporting and memory analysis
# – Add bypass mechanism for modules where this causes problems
import sys
import imp
import gc
import __builtin__
import zipimport
memory_query_func = None #set this to something returning memory use
verbose = False
ModuleType = type(sys)
#modules that bypass this mechanism
ignorenames = set() #module names
ignorepkg = set() #package names
ignorepath = set() #paths to ignore
#side effect register string unicode handling / conversion
ignorenames |= set([“encodings”])
#side effect prevent internal Python borrowed reference choking
ignorenames |= set([“warnings”])
#statistics
proxies = set()
proxyTally = 0
reals = set()
ignored = set()
existing = set(k for k,v in sys.modules.iteritems() if v)
def report(arg=””):
if not verbose:
return
loaded = arg.startswith(“load “)
if loaded:
if memory_query_func is not None:
print >> sys.stderr, “lazyimport: %s (now using %0.3f Mb)” % (arg, memory_query_func())
else:
print >> sys.stderr, “lazyimport: %s” % arg
else:
if memory_query_func is not None:
print >> sys.stderr, “lazyimport report: %s (now using %0.3f Mb)” % (arg, memory_query_func())
else:
print >> sys.stderr, “lazyimport report: %s” % arg
if verbose > 1 or not loaded:
print >> sys.stderr, “proxy imported %d %r”%(len(proxies), sorted(proxies))
print >> sys.stderr, “proxy imported (maximum size reached) %d” % proxyTally
print >> sys.stderr, “fully imported (pre lazyimport) %d %r”%(len(existing), sorted(existing))
print >> sys.stderr, “fully imported (via lazyimport) %d %r”%(len(reals), sorted(reals))
print >> sys.stderr, “fully imported (via allowed bypass) %d %r”%(len(ignored), sorted(ignored))
modules = set(k for k,v in sys.modules.iteritems() if v)
diff = modules-reals-proxies-ignored-existing
print >> sys.stderr, “fully imported (lost track of these) %d %r”%(len(diff), sorted(diff))
builtins = set(sys.builtin_module_names)
diff = builtins & proxies
print >> sys.stderr, “builtins (proxied) %d %r” % (len(diff), diff)
diff = builtins & (reals | existing)
print >> sys.stderr, “builtins (fully imported) %d %r” % (len(diff), diff)
diff = builtins – proxies – reals – existing
print >> sys.stderr, “builtins (not imported) %d %r” % (len(diff), diff)
def loadModule(proxy, name, loader):
#see if the module is already loaded
mod = sys.modules.get(name, None)
#avoid isinstace on mod, because it will cause __class__ lookup and this
#causes recursion
if mod is not proxy and isinstance(mod, ModuleType):
return mod
#load the module
mod = loader.load_module(name)
replaceModule(proxy, mod)
reals.add(name)
try:
proxies.remove(name)
except KeyError:
pass
report(“load “+name)
return mod
def replaceModule(proxy, mod):
“”” Find all dicts where proxy is, and replace it with the actual module.
Typcially, this is the sys.modules and any module dicts.
“””
for e in gc.get_referrers(proxy):
if isinstance(e, dict):
for k, v in e.iteritems():
if v is proxy:
e[k] = mod
class ModuleProxy(object):
def __init__(self, name, loader):
global proxyTally
object.__setattr__(self, “_args”, (name, loader))
proxies.add(name)
proxyTally += 1
#report(“proxy “+name)
# we don’t add any docs for the module in case the
# user tries accessing ‘__doc__’
def __getattribute__(self, key):
if key in [“_args”]:
return object.__getattribute__(self, key)
mod = loadModule(self, *self._args)
return getattr(mod, key)
def __setattr__(self, key, value):
mod = loadModule(self, *self._args)
setattr(mod, key, value)
def __dir__(self):
#modules have special dir handling, invoke that.
return dir(loadModule(self, *self._args))
def __repr__(self):
return “” %(self._args,)
class StandardLoader(object):
“”” A class that wraps the standard imp.load_module into
the new style object hook api, for consistency here
“””
def __init__(self, pathname, desc):
self.pathname, self.desc = pathname, desc
def __repr__(self):
return “” %(self.pathname, self.desc)
def load_module(self, fullname):
try:
f = open(self.pathname, ‘U’)
except:
f = None
try:
return imp.load_module(fullname, f, self.pathname, self.desc)
finally:
if f:
f.close()
class OnDemandLoader(object):
“”” The loader takes a name and real loader of the module to load and
“loads” it – in this case returning loading a proxy that
will only load the class when an attribute is accessed.
“””
def __init__(self, real_loader):
self.real_loader = real_loader
def load_module(self, fullname):
mod = sys.modules.get(fullname)
if not mod:
mod = ModuleProxy(fullname, self.real_loader)
sys.modules[fullname] = mod
return mod
class OnDemandImporter(object):
“”” The on-demand importer imports a module proxy that
inserts the desired module into the calling scope only when
an attribute from the module is actually used.
“””
def find_module(self, fullname, path=None):
if path:
#only bother with sub-modules if they are being loaded
#correctly, i.e. the parent module is already in sys.modules
head, tail = fullname.rsplit(‘.’, 1)
if not sys.modules.get(head):
return None
else:
tail = fullname
# See if the module can be found. It might be trying a relative
# import for example, so often modules are not found.
try:
f, pathname, desc = imp.find_module(tail, path)
if f:
f.close()
except ImportError:
return None #no zip found either
#Now, ignore some modules that we don’t want
#Since this is the meta_path, we just pass it on to the
#rest of the machinery, i.e. pretend not to have found it.
if ignore_module(fullname, pathname):
return None
#Ok, we are going to load this lazily
real_loader = StandardLoader(pathname, desc)
return OnDemandLoader(real_loader)
class OnDemandZipImporter(object):
def __init__(self, path):
importer = zipimport.zipimporter(path)
self.real_importer = importer
self.is_package = importer.is_package
self.get_code = importer.get_code
self.get_source = importer.get_source
self.get_data = importer.get_data
self.get_filename = importer.get_filename
def find_module(self, fullname, path=None):
result = self.real_importer.find_module(fullname, path)
if result is None:
return None
return self
def load_module(self, fullname):
if ignore_module(fullname, self.real_importer.archive):
return self.real_importer.load_module(fullname)
mod = sys.modules.get(fullname)
if not mod:
mod = ModuleProxy(fullname, self.real_importer)
sys.modules[fullname] = mod
return mod
onDemandImporter = OnDemandImporter()
RealReload = reload
def LazyReload(module):
if type(module) is ModuleType:
return RealReload(module)
def install():
if onDemandImporter not in sys.meta_path:
sys.meta_path.append(onDemandImporter)
try:
idx = sys.path_hooks.index(zipimport.zipimporter)
sys.path_hooks[idx] = OnDemandZipImporter
except ValueError:
pass
__builtin__.reload = LazyReload
def uninstall():
try:
sys.meta_path.remove(onDemandImporter)
try:
idx = sys.path_hooks.index(OnDemandZipImporter)
sys.path_hooks[idx] = zipimport.zipimporter
except ValueError:
pass
except ValueError:
return
__builtin__.reload = RealReload
def ignore_module(fullname, pathname=None):
“””
See if we want to ignore demand-loading of this module for any reason
“””
ignore = False
if fullname in ignorenames:
ignore = True
for pkg in ignorepkg:
if fullname.startswith(pkg):
ignore = True
if pathname:
for path in ignorepath:
if path in pathname.lower():
ignore = True
if ignore:
ignored.add(fullname)
return ignore
[/python]